What is Multimodal AI? A Complete Beginner’s Guide to AI That Understands Text, Images, and Voice
Imagine you are showing a photo of a broken dishwasher to a friend. You don’t just show the picture; you explain the clunking sound […]
Contributor
Imagine you are showing a photo of a broken dishwasher to a friend. You don’t just show the picture; you explain the clunking sound it makes and point to the leaked water on the floor. Your friend’s brain processes the image, your voice, and the context of your words all at once to tell you exactly what’s wrong.
For years, artificial intelligence couldn’t do that. It was single modal, good at reading text but blind to images, or great at identifying faces but deaf to the tone of your voice. That era is officially over.
What is Multimodal AI? A Complete Beginner’s Guide (2026)
In 2026, multimodal AI is the new standard. This technology allows AI to see, hear, and read simultaneously. It bridges the gap between machine logic and human-like perception. Multimodal AI is transforming how people interact with the digital world.
What is Multimodal AI? The Breaking News of 2026
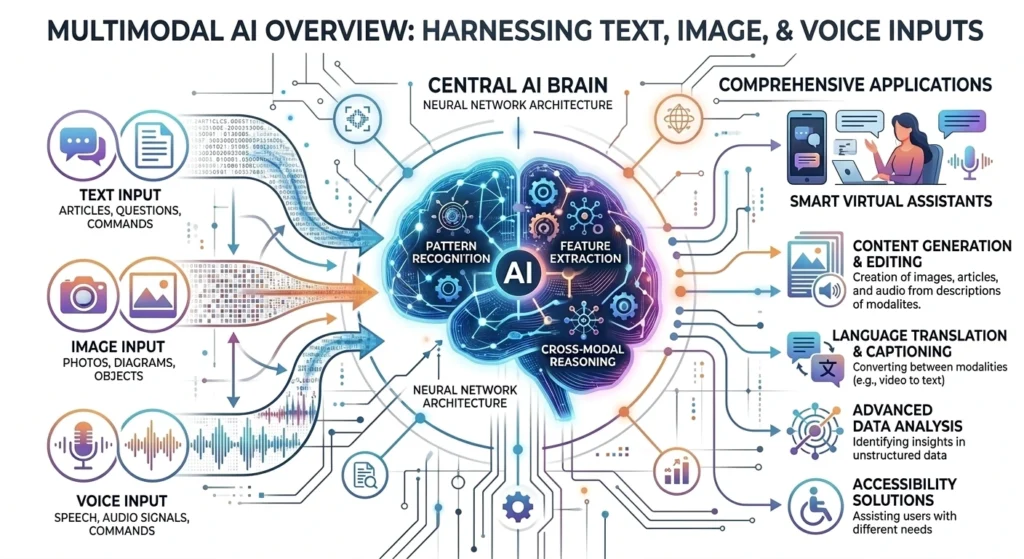
At its core, multimodal AI is a type of machine learning model. It is trained to process and integrate multiple modalities or types of data. These include text, images, audio, and video within a single framework.
The global AI market is projected to reach $335.29 billion by 2026. A major driver of this growth is the shift from text-only LLMs (Large Language Models) to LMMs (Large Multimodal Models).
The world is not just text. Humans experience reality through five senses. By giving AI, the ability to process diverse data streams, AI is moving toward General AI. This AI can navigate the physical and digital world with more nuance than ever before.
How a Multimodal AI Works: Under the Hood
To understand multimodal AI, one must look at how it thinks. It does not just look at an image and then read a caption separately. It uses a process called cross-modal reasoning.
The Translation Phase
Every piece of data is converted into a common numerical language called embeddings. This applies to a pixel in a photo or a frequency in a voice clip.
- Text Encoders: Convert words into vectors based on meaning.
- Vision Encoders: Turn visual patterns into mathematical representations.
- Audio Encoders: Translate sound waves into data points.
The Fusion Secret
The magic happens during fusion. The model aligns these different languages. The concept of golden retriever in text is mathematically linked to the visual of a furry dog and the audio of a bark. This allows the AI to answer complex questions.

The Titans of 2026: GPT-5, Gemini, and Claude
The AI Arms Race has shifted from the most parameters to who has the best multimodal reasoning. Three major players dominate the landscape as of late 2025 and early 2026:
- OpenAI GPT-5: Launched in August 2025, GPT-5 is a unified system. It has state-of-the-art visual perception and reasoning. It can handle deep extended reasoning for complex medical or engineering tasks.
- Google Gemini 2.5 Pro: It excels at processing massive multimodal inputs. This includes analyzing an hour-long video or a 1,000-page PDF with embedded charts in seconds.
- Anthropic Claude 4: Known for its Extended Thinking Framework, Claude 4 (released May 2025) is popular among developers. It focuses on high-stakes accuracy and agentic workflows. The AI can use tools to execute tasks after seeing a screenshot of a problem.
Real-World Examples: More Than Just a Chatbot
Multimodal AI is not just for fun it’s solving unsolvable problems in major industries.
Healthcare: The Second Reader
Doctors now use tools like Med-PaLM M and Microsoft-Nuance Dragon Medical One. These systems read a doctor’s handwritten notes and listen to the patient’s verbal complaints. This helps flag anomalies that a single test might miss.
Retail: The End of Running Shoes Searches
Instead of typing blue running shoes with arch support, users can snap a photo of a stranger’s shoes. Then, they can tell their phone, Find me these, but in red and for under $100. Multimodal AI analyzes the image, understands the voice command, and scans inventory prices simultaneously.
Education: The Personalized AI Tutor
Platforms like Khanmigo allow students to show a rough geometry sketch to their camera. The AI sees the mistake in the drawing and explains it verbally. This creates a true 1:1 tutoring experience at scale.

Challenges and Controversies: The Black Box Problem
Multimodal AI faces three major hurdles in 2026:
- Bias Amplification: If a model has bias in its text data and its image data, combining them can lead to even more discriminatory outcomes. This can occur in areas like hiring or law enforcement.
- Privacy Risks: These models are data-hungry. A healthcare app using your voice, images, and history creates a massive attack surface for potential data breaches.
- Compute Costs: Training a model to understand video and audio is incredibly expensive and energy-intensive. This has sparked a Green AI movement to find more sustainable ways to build these brains.
Future Outlook: Is Multimodal AI the Future?
Yes, multimodal AI is the future. Systems will power robots. When a robot can see a kitchen, hear you ask for a coffee, and read the instructions on a new espresso machine, the next stage of human-machine collaboration will be reached.
By 2031, the multimodal AI market is expected to reach $13.51 billion, with the fastest growth seen in real-time video processing.

Conclusion: Getting Started with Multimodal AI
Multimodal AI is in your pocket. From Google Lens to ChatGPT’s Voice Mode, people are already living in a multimodal world.
The best way for beginners to keep up is to experiment. Try uploading a photo of your fridge to a generative AI tool and ask for a recipe. Another option is to record a meeting and ask for a summary of the tone of the participants.
FAQs
1. What is multimodal AI?
It is AI that can process and integrate multiple types of data, such as text, images, and audio, simultaneously.
2. How does it work?
It uses encoders to translate different data types into a unified numerical language (embeddings) and fuses them to understand context across all formats.
3. What are examples of multimodal AI?
GPT-5, Google Gemini, and medical AI like Med-PaLM M are prime examples.
4. Why is it important?
It allows for more human-like, accurate, and versatile interactions, solving complex problems that text-only AI cannot.
5. Is multimodal AI the future?
Yes. It is the foundation for next-generation robotics, advanced healthcare, and hyper-personalized consumer tech.
Share this story
Related Articles
Lumio Project Neo Explained: What the AI-Powered WhatsApp Assistant Actually Does
Lumio Project Neo brings AI-powered content discovery to compatible Vision TVs and Arc Projectors through WhatsApp and Instagram. Here's what is officially confirmed.

Top Smart Gadgets in 2026: AI-Powered Devices Changing Everyday Life
In 2026, your home doesn’t just wait for your command; it anticipates your needs. Welcome to the world of smart gadgets 2026, where artificial intelligence […]
15 Best AI Tools 2026 for Productivity, Content Creation, and Daily Tasks
As we navigate through 2026, Artificial Intelligence hasn’t just evolved it has become the very fabric of our digital existence. From agents that manage […]
Comments (0)